Mythos Madness #3: The Harness
A model is the talent. The harness is the operation. A tiny model went from 60% to 94.8% on MATH-500 with nothing but harness changes. The harness is where the leverage is.
In Part 1, I showed that a maximalist underwriting review costs about $40 at Mythos pricing. In Part 2, I showed that a 15-cent model can handle routine tasks just as well as an expensive capable beast. Both assumed something I didn't name: the harness.
What's a Harness?
Think about a brilliant underwriter. Fast. Efficient. Knowledgeable. Productive as hell.
Now take away her wi-fi.
Her productivity plummets as she tries to type with her thumbs and read loss control reports on her iPhone. Spreadsheets become hard to read. Dense reports become impossible. She's the brains of the outfit, but take away the things that surround her and make her productive, and she should just take the day off.
LLMs, even, or especially powerful ones, need systems surrounding them to be productive. That's what a harness provides: the tools, the connections, the agentic loops that let the model actually do work.
The Industry Figured This Out
A year ago, the consensus was simple: build a bigger model, get a better result. Raw intelligence was the bottleneck. Make the model smarter and the output improves.
That viewpoint is dead.
Every company that builds frontier models is now building harnesses. Anthropic built Claude Code. OpenAI built Codex. Google built Jules. Startups like Manus got acquired specifically for their harness technology, not their models.
And it's not just coding. OpenClaw is a harness that orchestrates multiple models to do real work, the kind of work that falls apart when you stuff it into a chatbot and hope for the best. These harnesses are emerging across domains, wherever there's a gap between "model can do this in theory" and "model actually does this reliably."
What the last year has made clear: models are getting more powerful. But the harnesses are what enable them to do transformative work.
I Tested This Myself
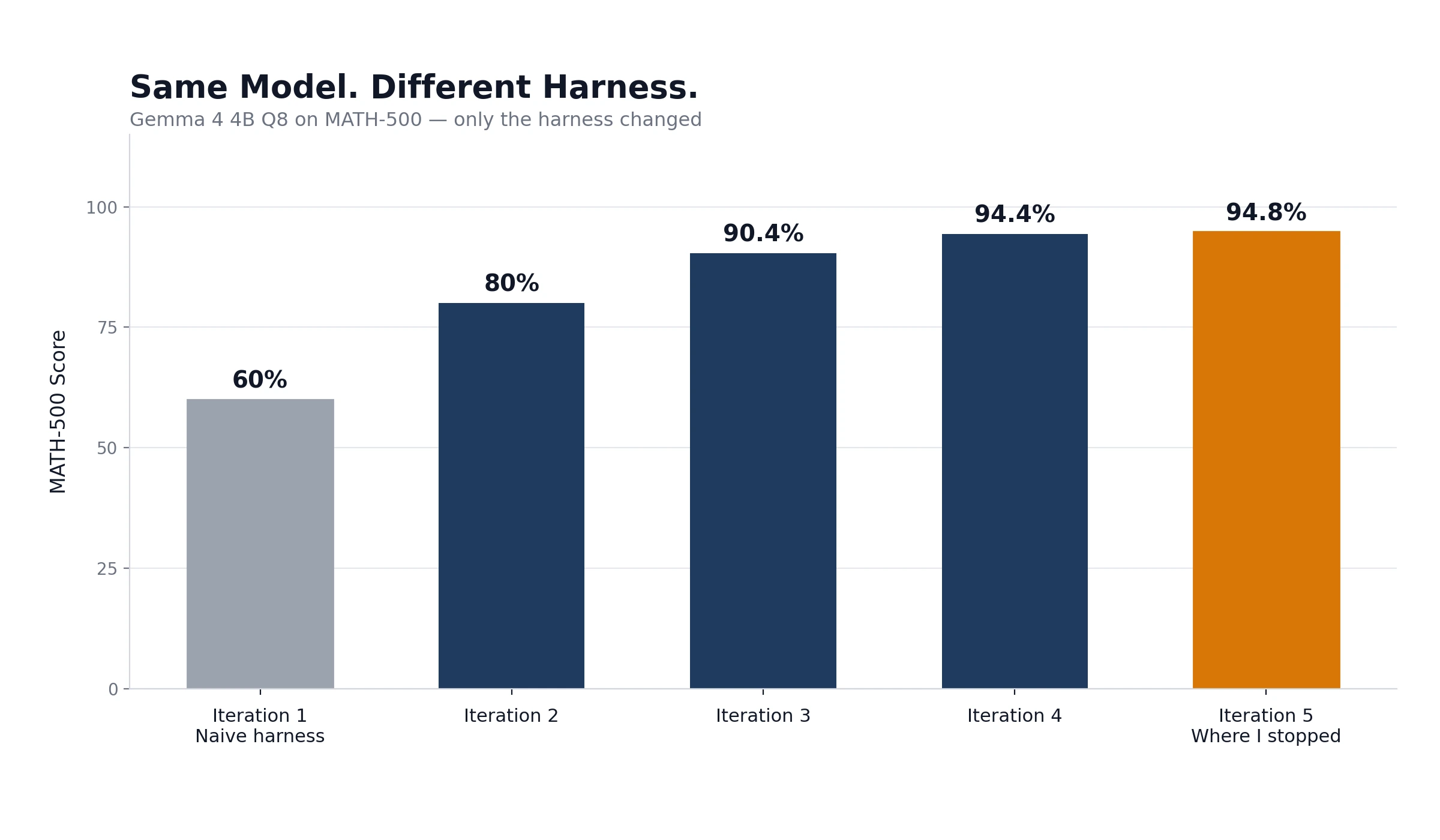
I built a testing harness for Gemma 4 4B Q8 on MATH-500, a standardized math benchmark. Gemma 4 4B is a tiny model, hundreds of times smaller than the frontier giants.
My first run scored 60%. The harness was naive and poorly built.
A few rounds of improvement later, the same model scored 94.8%. A genuinely competitive number.
What changed? Not the model. The harness.
Better input prompts. Smarter answer recognition, teaching the scorer that "11111111100" and "11,111,111,100" are the same number. Cleaner output parsing. Simple stuff. All fair. All honest.
I stopped at 94.8% because this was a test. In a real deployment I'd have kept going. Another half point or full point was almost certainly sitting there, waiting for the next round of tweaks. That's the nature of harness work: the returns keep coming as long as you keep looking.
The upshot: if you're building harnesses, testing and hunting for errors can move your results dramatically. This was a simple case, but with the original naive harness, the most powerful model in the world might have underperformed a tiny model in a better harness. The harness is that consequential.
The Senior and the Junior
Here's where it gets interesting for insurance.
A harness doesn't just wrap one model. It orchestrates multiple models, selecting the right one for each phase of the work.
Think of Mythos as the senior underwriter. Powerful. Expensive. You want her answering the hard questions, the ones that require judgment, context, and reasoning across a complex submission.
Now think of a small model, say, Google's Gemma 4, as the junior underwriting assistant. Doesn't know as much. Not even close. But can extract data from an Acord app, normalize loss run formats, and flag missing documents. Fast. Cheap. Reliable on targeted tasks.
But it's not a binary. Between Gemma 4 and Mythos sits a wide field of models, cheaper than the frontier, more capable than the tiny ones, each with their own strengths. Gemma 4 can't handle everything the junior assistant role demands. Plenty of models well short of Mythos can. Finding the ones that work for each slice of the job is part of building the harness.
The harness oversees the work and provides the tools. It routes each task to the model best suited for it, structured so that model can do its best work, with oversight to catch errors. The junior handles what the junior can handle. Mid-tier models pick up what's beyond the junior. The hardest reasoning goes to the top.
Along the way, you'll find something counterintuitive: for some tasks, a smaller model with a well-defined harness won't just be cheaper. It will outperform the bleeding-edge model saddled with an ill-fitted harness and poor direction.
Think about a human senior underwriter forced to pull data from a weird legacy system she's never been trained on. Slow. Error-prone. Her real talents wasted on plumbing. Good work process keeps that from happening to humans. A good harness is what keeps that from happening to the models.
What This Means
If you're evaluating AI for underwriting, or any insurance operation, stop asking "which model is best?" Start asking "what's the harness?"
The model is the talent. The harness is the operation. You need both. But the operation is where the leverage is.
A vendor wants to sell you tokens. You want to use them effectively. Before you pay for an expensive model, make sure you're set up to use it well. That means a well-built harness.
Part 1 showed you the ceiling. Part 2 showed you the floor. This is the machinery that connects them.